
In the digital age, finding the right information feels like looking for a needle in a haystack. Whether you are shopping for a specific gadget or researching a complex scientific topic, you expect the search bar to understand exactly what you mean. However, standard search engines often miss the mark, returning results that are somewhat related but not quite right. This is where the powerful combination of Rerankers and two-stage retrieval comes into play. This brilliant strategy is transforming how machines understand our needs, making search systems smarter, faster, and surprisingly intuitive. In this guide, we will explore how this technology works, why it matters, and how it is revolutionizing everything from online shopping to artificial intelligence.
The Problem with Simple Search
Imagine you are in a massive library looking for a “novel about dinosaurs.” A simple search system acts like a helpful but overly literal assistant. It rushes to the shelves and grabs every book that contains the word “dinosaur.”
You might end up with a pile containing a children’s coloring book, a dense encyclopedia on fossils, and a scientific paper on the Cretaceous period. While these are technically matches, they aren’t what you wanted. You wanted Jurassic Park. This limitation exists because standard retrieval systems often prioritize speed and keyword matching over deep understanding. They are great at creating a shortlist but terrible at picking the winner. This is why Rerankers and two-stage retrieval have become an essential tool for developers and data scientists.
What is Two-Stage Retrieval?
Two-stage retrieval is exactly what it sounds like: a search process split into two distinct steps to balance speed and accuracy. It is the technological equivalent of having two different experts help you find that book.
RAG-LLMs generally adopts a two-stage pipeline. The first stage conducts fast but low-precision (embedding model) retrievals, while the second stage (rerankers) emphasizes high-precision but higher computational costs for a trade-off between effectiveness and efficiency (Haotian Chen, 2025).
- The Retriever (Stage 1): This is the “fastnet.” It casts a wide net to quickly identify a broad set of potentially relevant items from a massive dataset. It doesn’t need to be perfect; it just needs to be fast and ensure the right answer is somewhere in the pile.
- The Reranker (Stage 2): This is the “expert filter.” Once the retriever has gathered a manageable list (say, 50 items), the reranker steps in. It reads through these specific items carefully, analyzing the context and intent behind your query to reorder them. The most relevant item is pushed to the top.
By combining these two, it can offer the best of both worlds: the speed to search billions of documents and the intelligence to understand human nuance.
Stage 1: The Retriever
The first stage relies on a technology called “embedding models.” When you type a query like “What camera to bring for my ski trip?”, the system converts your words into a “vector” – a complex list of numbers that represents the meaning of your sentence.
The system then compares this vector to the vectors of all the products in its database. It looks for items that are mathematically close to your query. This is incredibly efficient for searching through millions of items. In our example, the retriever might pull up 50 cameras. Some might be action cameras (good matches), while others might be security cameras (bad matches) simply because they share keywords like “durable” or “outdoor”.
While vector search is a massive leap forward from old-school keyword matching, it isn’t perfect. It often misses specific details because it “compresses” the meaning of a text into a single vector. It effectively finds the right neighborhood of answers but doesn’t always knock on the right door. This is why we cannot rely on retrieval alone.
Stage 2: The Reranker
The initial heavy lifting is done by fast and efficient embedding-based vector search, which retrieves a set of documents from an extensive knowledge base but may lack the high precision required in some use cases. Rerankers then refine a set of candidates, providing the most relevant documents to improve the retrieval accuracy.
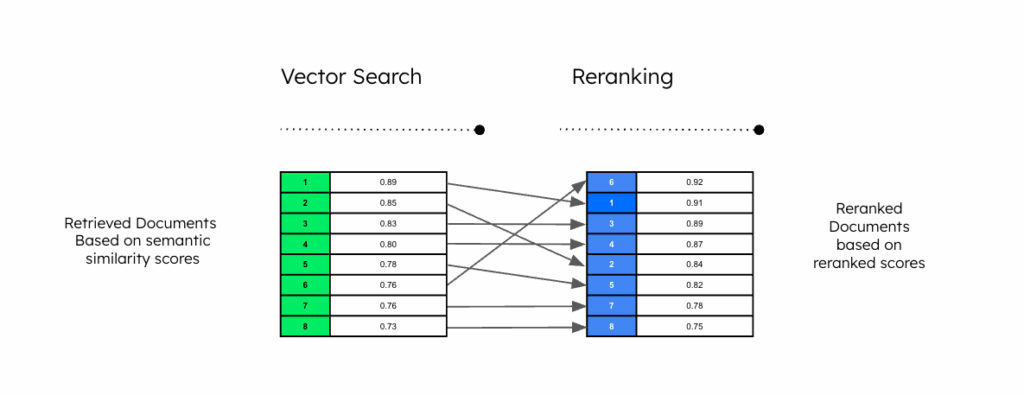
This is where the magic happens. A reranker is a specialized model designed to score the similarity between a query and a document with high precision. Unlike the retriever, which uses pre-calculated vectors, the reranker looks at the query and the document text together in real-time.
In our ski trip example, the reranker would examine the 50 cameras found by the retriever. It would understand that “ski trip” implies cold weather, snow, action, and portability. It would see a “Lorex Outdoor Security Camera” and rank it low because, although it is durable, you can’t strap it to a helmet. Conversely, it would see a “GoPro” or a distinct action camera and rank it high because it fits the specific context of a ski trip.
Implementing Rerankers and two-stage retrieval allows systems to utilize powerful models like BERT or BGE-M3 without sacrificing speed. Running a heavy, smart model on a million documents would take hours. Running it on just the top 50 results takes milliseconds. This efficiency is the core reason why this is becoming the industry standard.
Benefits of Rerankers
The adoption of Rerankers and two-stage retrieval provides significant advantages that go beyond just “better search results.”
- Improved Accuracy: The most obvious benefit is that users find what they need faster. In academic benchmarks, reranking consistently outperforms single-stage retrieval, especially for complex scientific queries where precise terminology matters.
- Contextual Understanding: They can distinguish between “apple” the fruit and “Apple” the technology company, based on the surrounding words in a way that simple keyword searches cannot.
- Handling Noisy Data: In real-world scenarios, databases are filled with irrelevant or low-quality information. A reranker acts as a quality control gate, ensuring that “noisy” or irrelevant documents don’t make it to the final output.
- Better Conversational AI: For chatbots and AI assistants using Retrieval Augmented Generation (RAG), the quality of the answer depends entirely on the quality of the retrieved information. If the AI reads the wrong document, it gives the wrong answer. Reranking ensures the AI is “reading” the right source material.
Real-World Application: E-Commerce
Let’s look closer at the e-commerce example. Online stores function on product recommendations. If a user searches for “laptop for graphic design,” a standard search might return the best-selling laptops, which could be cheap Chromebooks. These are popular, but terrible for graphic design.
The system first pulls all laptops (Stage 1). Then, the reranker sorts them based on the “graphic design” intent, prioritizing machines with high-resolution screens and powerful graphics cards (Stage 2). The result? The customer sees exactly what they need immediately, leading to happier customers and higher sales.
This method is flexible, too. Businesses can inject other metadata into the reranking logic, such as prioritizing items that are currently in stock or on sale, ensuring the recommendations are not only relevant but also actionable.
Real-World Application: Smarter Chatbots (RAG)
One of the most exciting applications is in Retrieval Augmented Generation (RAG). This is the technology behind custom AI chatbots that can answer questions about your specific documents.
In a practical coding experiment using the CoHere model and LangChain, developers compared a standard RAG pipeline against one using a reranker. They asked, “What is the architecture of DistilBERT?”
- Without Reranking: The system retrieved somewhat relevant documents but missed the specific technical details. The AI’s answer was generic, stating DistilBERT is “smaller and faster” but lacking depth.
- With Reranking: The system successfully identified the exact sections of the academic paper describing the architecture. The AI’s answer was rich and precise, noting that DistilBERT “retains 97% of the language understanding capabilities of BERT” and uses a “triple loss” function. The AI is ensured to have the best possible notes to study from before answering the question.
This difference highlights why Rerankers and two-stage retrieval are critical for building reliable AI products. It is the difference between an AI that guesses and an AI that knows.
The Future of Search
As our digital libraries grow and our questions become more complex, the need for sophisticated retrieval methods will only increase. Rerankers and two-stage retrieval are no longer just experimental techniques; they are becoming the backbone of modern information systems. From helping scientists navigate millions of research papers to helping you find the perfect pair of winter boots, this technology is working silently in the background to make our digital lives easier.
The beauty of this approach lies in its balance. It acknowledges that we need the speed of broad search but refuses to compromise on the intelligence of deep understanding. By marrying the efficiency of retrieval with the precision of reranking, developers can build systems that truly understand human intent. Whether you are a developer looking to optimize your application or a business leader wanting to improve customer experience, mastering Rerankers and two-stage retrieval is the perfect match for success in the data-driven world.
Ready to upgrade your search capabilities?
At Verysell AI, we deliver cutting-edge AI solutions and conversational AI chatbots tailored to your unique needs. Let our team of excellent engineers help you implement smart two-stage retrieval systems that drive real results. Contact us today to transform your user experience.