In the rapidly evolving landscape of Large Language Models (LLMs), a critical bottleneck has emerged: knowledge stagnation. Once an AI model is trained, its internal knowledge is frozen in time. To bridge the gap between static training data and the dynamic real world, researchers and engineers have turned to a powerful paradigm known as Retrieval Augmented Generation (RAG). This article explores the mechanics of RAG, effective approaches, methods for improvement, and cutting-edge innovations like Parametric and Dynamic RAG, based on the latest academic research.
1. What is RAG?
Retrieval Augmented Generation (RAG) is a technique designed to enhance the reliability and accuracy of Large Language Models by granting them access to external, up-to-date information. At its core, standard LLMs rely on “parametric memory”, the knowledge stored within their neural network weights during training. While impressive, this memory is static. It cannot answer questions about events that happened after its training cutoff, nor can it access private, domain-specific data (like a company’s internal wiki).
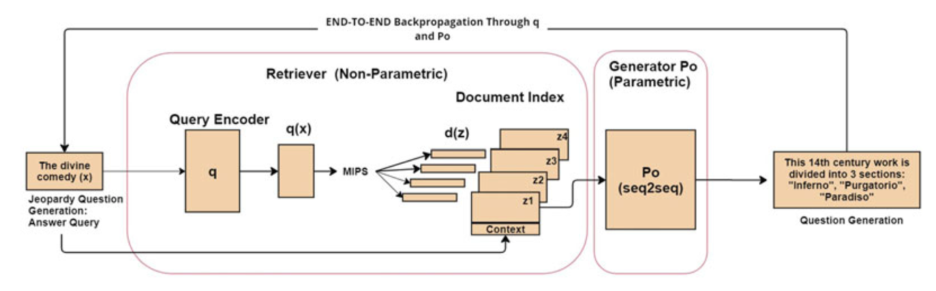
RAG solves this by introducing a retrieval step before generation. Instead of relying solely on internal memory, the system: Retrieves relevant documents from an external corpus (like Wikipedia or a private database) based on the user’s query. Augments the input to the LLM by combining the user’s query with these retrieved documents. Generates a response using this enriched context. This process helps mitigate hallucinations (where the AI confidently invents facts) and allows for domain adaptation without the massive expense of retraining the model.
2. Approach: The Standard RAG Pipeline
The standard RAG workflow, often referred to as “In-Context RAG,” generally follows a “Retrieve-then-Generate” process.
The Mechanism
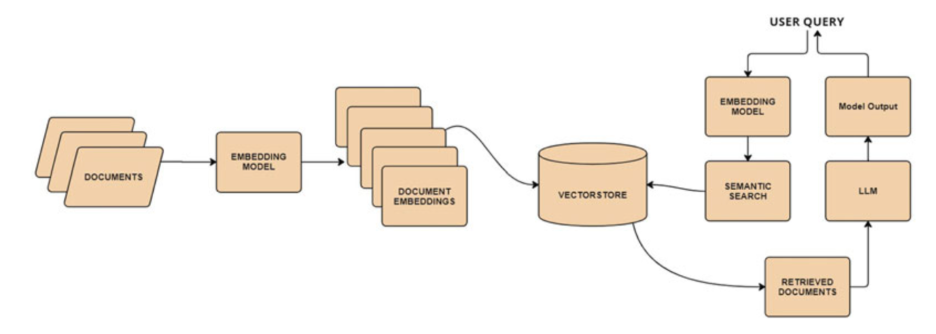
Phase 1: Preprocessing and Indexing (Data Pre-ingestion)
This phase is conducted offline and sets up the knowledge base. This is where the raw data is transformed into a searchable format.
- Data Ingestion: Collect raw, unstructured data (documents, PDFs, web pages, internal reports) from various sources.
- Chunking and Segmentation: The large, raw documents are broken down into smaller, manageable, and semantically coherent units called chunks. This is critical because an LLM’s context window has a size limit, and retrieval systems perform better when matching a query to a concise block of relevant text, rather than a massive document.
- Embedding/Vectorization: Each text chunk is passed through an Embedding Model (e.g., a specialized Sentence Transformer or an OpenAI/cohere model) to convert the text into a numerical vector representation. These vectors encode the semantic meaning of the text.
- Vector Database Storage: These vectors, along with a pointer to the original text chunk, are stored in a Vector Database (e.g., ChromaDB, Pinecone, or FAISS). This database is optimized for fast Approximate Nearest Neighbor (ANN) search, forming the searchable index.
Phase 2: Inference (Retrieve-Augment-Generate)
This phase happens in real-time when a user submits a query.
- Query Encoding: The user’s question (query) is converted into a vector representation using the same Embedding Model used in Phase 1.
- Retrieval: The query vector is used to perform a search in the Vector Database. The system retrieves the top-$k$ document vectors that are closest (most semantically similar) to the query vector.
- Context Augmentation: The retrieved text chunks are extracted and concatenated with the original user query, forming an enriched prompt. This acts as the external context.
- Generation: The enriched prompt is sent to the Large Language Model (LLM). The LLM uses its internal (parametric) knowledge alongside the external (non-parametric) context to generate the final, grounded answer.
While effective, this “in-context” approach has inherent flaws. Injecting long documents into the prompt increases computational overhead and latency. Furthermore, LLMs process information in the prompt differently than knowledge stored in their own parameters. There is often a “gap” between how a model uses its internal instincts versus how it interprets external text pasted into a prompt.
3. How to Improve RAG
The performance of a RAG system is not determined by the LLM alone, but by the efficiency and quality of every component in the pipeline. Research by Şakar and Emekci emphasizes a principled, measurement-driven development cycle to maximize RAG efficiency, advocating for systematic tuning and evaluation rather than relying on a single default setup. The recommendations below synthesize the principal findings and operational prescriptions for enhancing RAG systems, spanning both the pre-ingestion and inference phases.
Phase A: Optimizing Pre-Ingestion (Indexing)
The quality of the knowledge base is paramount. Optimization here focuses on how data is structured and vectorized before it is queried.
Corpus Preprocessing: Principled Chunking and Overlap
The authors emphasize that chunk size and overlap strategy materially affect retrieval granularity and downstream answer synthesis. Tune chunk boundaries and overlap parameters to avoid both the fragmentation of coherent passages (losing context) and excessive redundancy in retrieved context.
Careful Selection and Evaluation of Embedding Models and Vector Stores
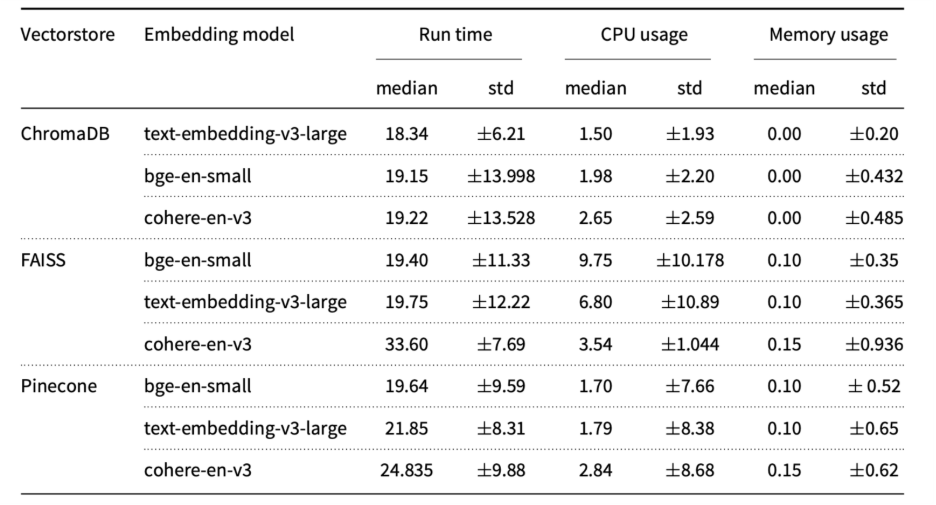
Figure 3. Metrics of usage for large language models and different embedding models
Empirical comparisons indicate substantial variance across embedding models with respect to semantic similarity and downstream accuracy (e.g., Bge-en-small performed strongly on evaluated corpora). Vector store choice (e.g., Chroma, FAISS) is likewise consequential for runtime and resource usage. Advocate ablation-style testing of multiple embedding/vector store combinations to find the optimal pair for your specific data and hardware.
Optimize Retrieval/Indexing Algorithms for Scale and Latency” The study documents benefits from using hardware-optimized Approximate Nearest-Neighbour (ANN) indices. Tune the trade-offs between search accuracy and throughput (a key parameter in ANN algorithms) to match application constraints.
Phase B: Optimizing Retrieval and Generation (Inference)
Once the knowledge base is indexed, the focus shifts to how the system retrieves and uses that context efficiently.
Stuff method
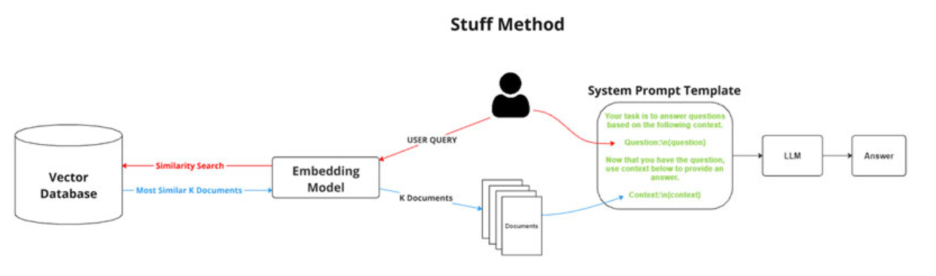
This is the most basic RAG technique. It works by retrieving all relevant documents and inserting (“stuffing”) them directly into the LLM’s prompt window as a single block of context to generate a response. While effective for creating comprehensive answers, it can be cost-inefficient and may exceed token limits if the retrieved documents are lengthy.
Refine method
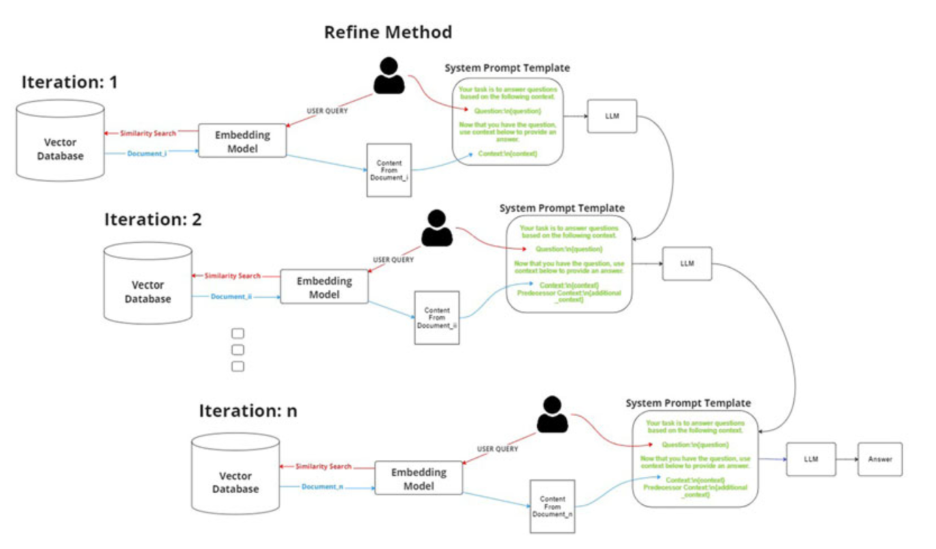
This iterative approach processes documents one by one. It generates an initial answer using the first retrieved document and then loops through the remaining documents to update and “refine” that answer based on new information. This allows the system to handle more content than fits in a single context window, though it significantly increases latency and the number of LLM calls.
Map-reduce method
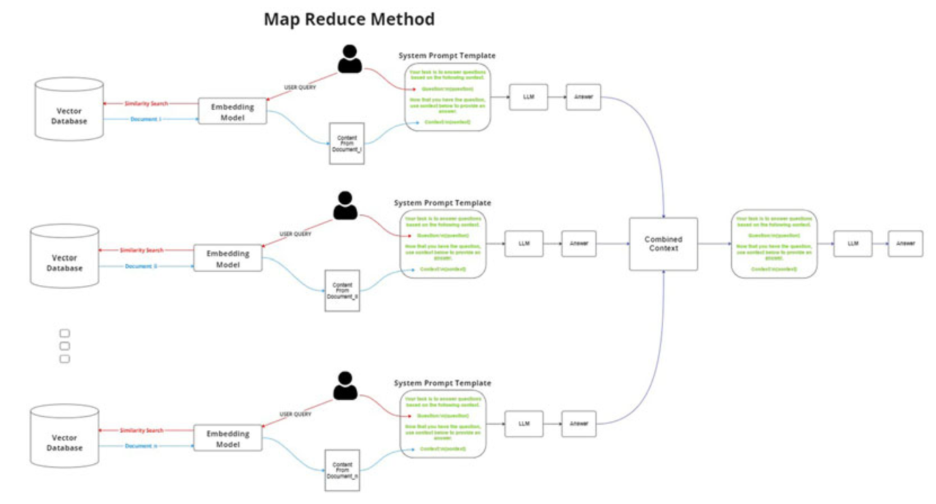
In this workflow, the model first processes each retrieved document independently to generate individual responses (the “mapping” phase). These separate responses are then consolidated into a single, final output (the “reducing” phase). This method is useful for parallel processing but adds complexity to the pipeline.
Map Re-rank
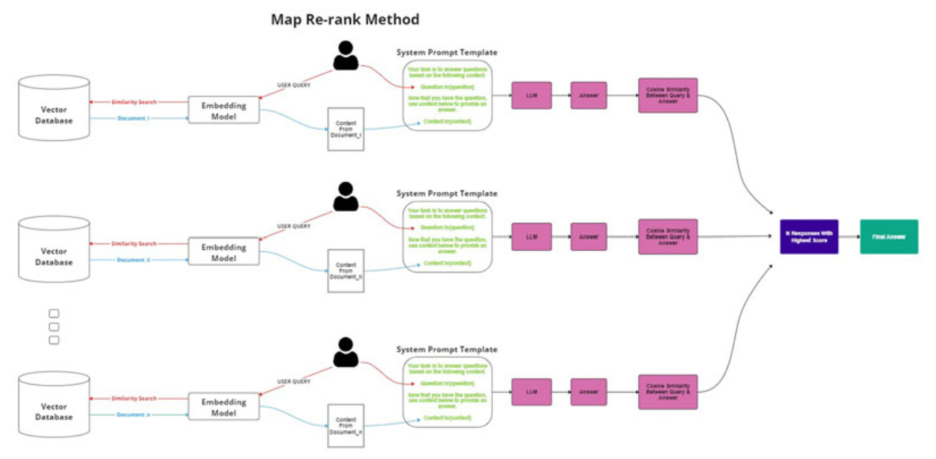
This method involves running a prompt on each retrieved document individually to generate both a potential answer and a confidence score. The system then compares these scores and selects the answer with the highest confidence rating. This approach is excellent for precision but is computationally expensive due to the high number of API calls required.
Reciprocal RAG
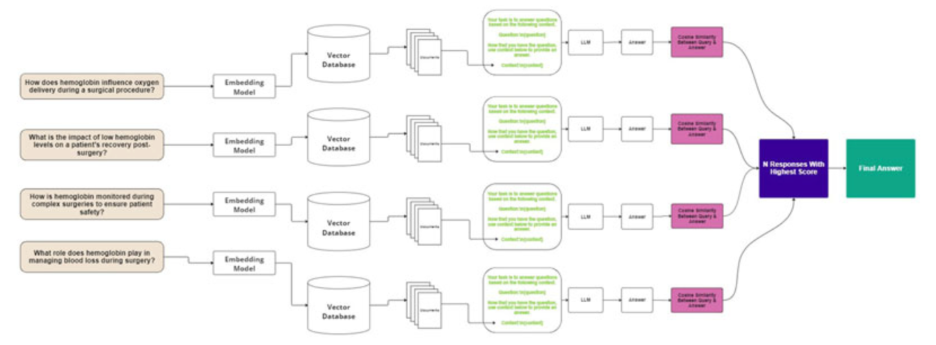
Designed to tackle ambiguous queries, this advanced method generates multiple potential answers or intermediate questions based on the retrieved documents. It then ranks these various outputs to find the most consensus-based or relevant response. It generally yields higher similarity scores but comes with higher computational costs.
Contextual Compression
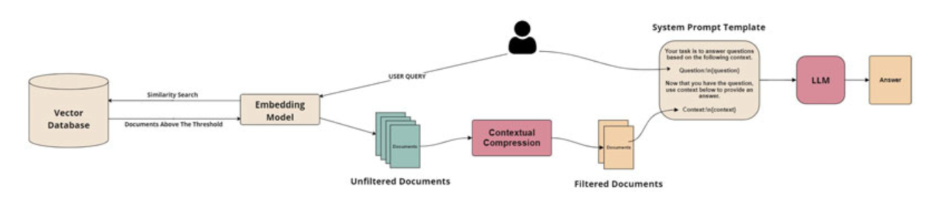
This strategy addresses the inefficiency of “noise” (irrelevant information) within retrieved documents. By applying similarity thresholds, it filters out irrelevant sections of text before they reach the LLM. This compresses the context, reducing token usage and costs while helping the model focus on the most critical facts.
Query Step-Down method
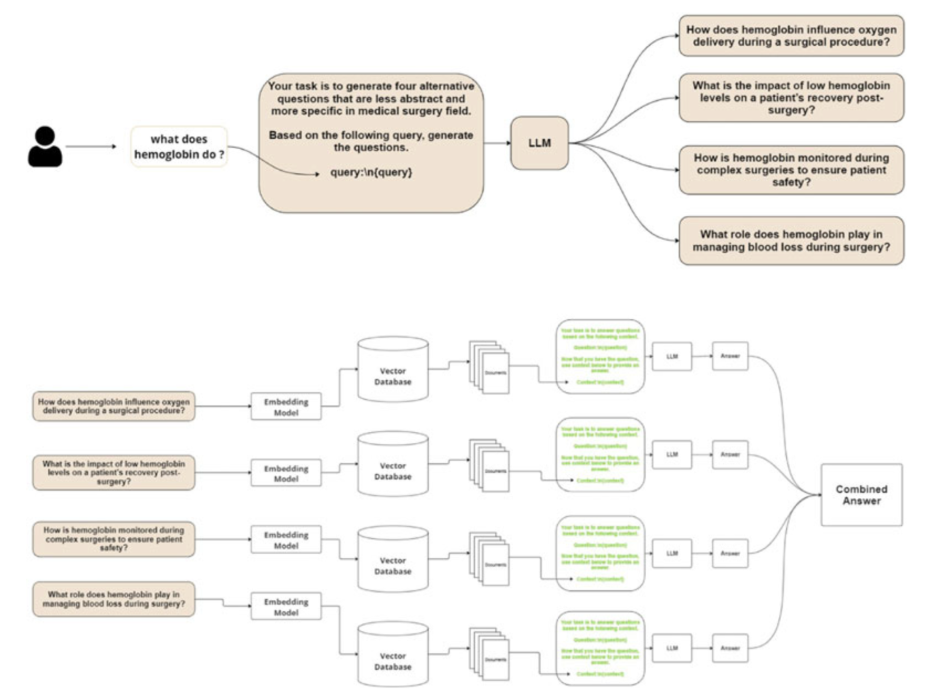
This optimization focuses on the underlying infrastructure. It highlights that the choice of vector store (e.g., ChromaDB, FAISS) and embedding model (e.g., OpenAI vs. BAAI) significantly impacts system performance. Selecting the right combination is crucial for optimizing runtime speed and hardware CPU utilization in high-volume applications.
4. Parametric RAG and Dynamic RAG
A groundbreaking evolution in this field is Parametric RAG. While traditional RAG keeps external knowledge in the prompt (non-parametric), Parametric RAG attempts to move this knowledge directly into the parameters of the model on the fly.
The Concept
Instead of pasting text into the input window, Parametric RAG encodes retrieved documents into a small set of neural network weights (specifically, low-rank adaptations or LoRA). When a document is retrieved, its specific “knowledge weights” are temporarily merged into the LLM’s Feed-Forward Networks (FFN).
How It Works
- Offline Parameterization: Documents are pre-processed into “Parametric Representations.” This involves augmenting the document (rewriting it and generating QA pairs) and then training a tiny adapter (LoRA) on this data.
- Retrieve-Update-Generate: During inference, the system retrieves the relevant “weights” (not just text). It updates the LLM by merging these weights into the model and then generates the answer.
Benefits
- Efficiency: It saves massive amounts of compute during inference because you aren’t processing thousands of input tokens in the prompt. The inference complexity remains low regardless of how much knowledge you inject.
- Knowledge Integration: It bridges the gap between external and internal knowledge. The model “knows” the retrieved information as if it learned it during training, leading to better multi-hop reasoning capabilities.
- Combination: Interestingly, Parametric RAG can be combined with traditional In-Context RAG to achieve even higher performance.
Another major challenge in RAG is determining how much information to retrieve. A static number (e.g., “always retrieve the top 5 documents”) is suboptimal; simple queries need fewer documents, while complex reasoning needs more. DynamicRAG introduces an intelligent “Reranker Agent” that dynamically adjusts the number and order of retrieved documents based on the specific query. DynamicRAG models the reranker as an agent optimized via Reinforcement Learning (RL).
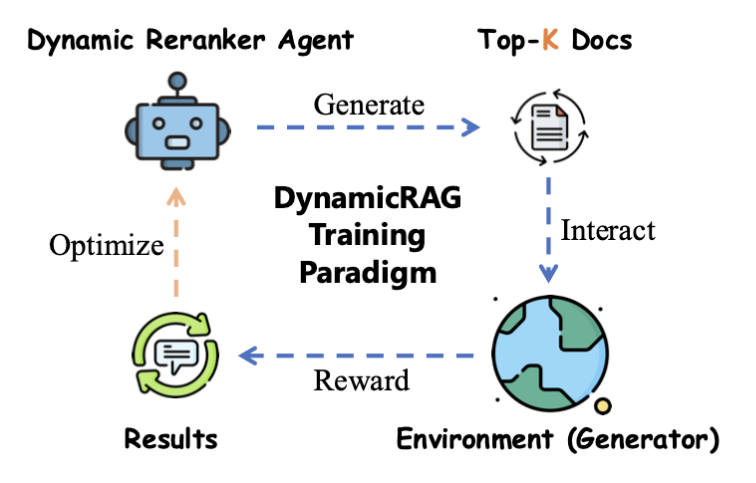
- Agent-Based Reranking: The reranker doesn’t just score documents; it decides the optimal set size (k). It stops selecting documents once it believes it has enough information to answer the query, reducing noise16.
- Feedback Loop: The system uses the quality of the LLM’s final generated answer as a reward signal. If the LLM answers correctly with fewer documents, the reranker is rewarded. This aligns the retrieval process directly with the end goal: generation quality.
This approach mitigates the “lost-in-the-middle” phenomenon where adding too many documents confuses the model. By dynamically sizing the context, DynamicRAG achieves State-of-the-Art (SOTA) results with greater efficiency, often requiring fewer LLM calls and less token usage than static methods.
5. RAG vs. Fine-Tuning
A common debate in AI engineering is whether to use RAG or to Fine-Tune the model on new data. The research suggests they serve different purposes but can be complementary. Fine-Tuning is excellent for teaching a model how to speak, follow instructions, or adhere to a specific format. However, it is computationally expensive to update frequently, and models can still hallucinate facts they were fine-tuned on. It does not solve the issue of accessing real-time data. While RAG is a superior for factual accuracy and accessing dynamic, rapidly changing data. It allows the model to cite sources and explain its reasoning. However, “In-Context” RAG can be computationally heavy due to long prompts.
Parametric RAG offers a middle ground. It essentially performs “instant fine-tuning” by injecting knowledge weights at runtime. This avoids the static nature of traditional fine-tuning while gaining the deep knowledge integration that fine-tuning offers, without the high context cost of standard RAG.
6. Integrate RAG with Verysell AI
Retrieval Augmented Generation is shifting from a static “search-and-paste” mechanism to a dynamic, sophisticated cognitive process.
- Standard RAG provided the foundation, proving that LLMs could reason over external data.
- Parametric RAG is revolutionizing efficiency, proving we can inject knowledge directly into a model’s “brain” (weights) rather than just its “eyes” (context window).
- Dynamic RAG is introducing agency, allowing systems to intelligently decide how much knowledge is needed, mimicking human research behavior.
As these technologies converge, we are moving toward AI systems that are not only knowledgeable but also efficient, adaptable, and self-optimizing. For developers and researchers, the future lies in combining these approaches using dynamic agents to select the best knowledge and parametric injection to seamlessly integrate it. Contact Verysell AI to explore more about our services and solutions!